Modellépítés / modellszelekció
- optimális eset: elméletvezérelt modellépítés
- gyakoribb eset: adatvezérelt modellépítés
- döntési pontok: fix hatások és random hatások, random hatáson belül random konstans és random slope -> kevés változó esetén is nagyon komplex lehet!
Javaslatok
- inkább haladjunk a bővebb modell felől
- először random hatások, utána fix hatások tesztelése
- a random hatásoknál érdemes a maximális struktúrát megtartani (feltéve, hogy konvergál)
- a random hatásokat REML, a fix hatásokat ML becsléssel teszteljük (a végső modell paramétereit REML becsléssel számoljuk)
- a modellszelekció történhet likelihoodarány-teszttel vagy pl. AIC-értékek összevetésével
- ha két fix hatás interakciója szerepel a modellben, akkor mindig vegyük be a főhatásokat is, illetve szerepeltessük az interakciót a random struktúrában is
Példa
Egy lehetséges induló modell
- modellezzük a válaszidőt (RT) a próba sorszáma (scTrial) és a személy anyanyelve, illetve a szó szemantikai kategóriája alapján
( model_full <- lmer(scRT ~ scTrial + NativeLanguage*Class +
(1 + scTrial | Subject) +
(1 | Page) + (1 | Word),
data = lexdec_corr) )
## Linear mixed model fit by REML ['lmerMod']
## Formula:
## scRT ~ scTrial + NativeLanguage * Class + (1 + scTrial | Subject) +
## (1 | Page) + (1 | Word)
## Data: lexdec_corr
## REML criterion at convergence: 1329.928
## Random effects:
## Groups Name Std.Dev. Corr
## Word (Intercept) 0.15977
## Subject (Intercept) 0.25896
## scTrial 0.06166 -0.40
## Page (Intercept) 0.91925
## Residual 0.33315
## Number of obs: 1594, groups: Word, 79; Subject, 21; Page, 10
## Fixed Effects:
## (Intercept) scTrial NativeLanguage1
## 0.029695 -0.018805 -0.162017
## Class1 NativeLanguage1:Class1
## 0.004267 -0.020760
örök FAQ: miért nem számol az lmer p-értékeket?: ezért
az lmer outputja a regressziós modellek outputjának formátumát követi; mit tegyünk, ha mi ANOVA-stílusú táblázatot szeretnénk?
library(car)
Anova(model_full)
## Analysis of Deviance Table (Type II Wald chisquare tests)
##
## Response: scRT
## Chisq Df Pr(>Chisq)
## scTrial 1.3930 1 0.237891
## NativeLanguage 9.0373 1 0.002645 **
## Class 0.0024 1 0.961226
## NativeLanguage:Class 5.9144 1 0.015018 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Anova(model_full, test.statistic = "F")
## Analysis of Deviance Table (Type II Wald F tests with Kenward-Roger df)
##
## Response: scRT
## F Df Df.res Pr(>F)
## scTrial 1.3927 1 25.62 0.248800
## NativeLanguage 8.6191 1 25.02 0.007037 **
## Class 0.0024 1 68.58 0.961397
## NativeLanguage:Class 5.9106 1 1482.68 0.015168 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
# az SPSS és SAS a Type III felbontást részesítik előnyben
Anova(model_full, type = 3)
## Analysis of Deviance Table (Type III Wald chisquare tests)
##
## Response: scRT
## Chisq Df Pr(>Chisq)
## (Intercept) 0.0100 1 0.920333
## scTrial 1.3930 1 0.237891
## NativeLanguage 8.8849 1 0.002875 **
## Class 0.0381 1 0.845312
## NativeLanguage:Class 5.9144 1 0.015018 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Random hatások tesztelése
- elsősorban akkor szükséges, ha túl komplex az induló modell, és/vagy szélsőséges értékek szerepelnek a varianca-kovariancia mátrixban (pl. 1 vagy -1 közeli korreláció és/vagy 0 szórás)
- az
anova.merModfüggvény használható, de valószínűleg túl konzervatív (szélsőséges esetben akár 2-szerese a p-érték a valósnak) - használhatjuk az AIC (vagy BIC) kritériumot is
# modellek illesztése
( model_r1 <- lmer(scRT ~ scTrial + NativeLanguage*Class +
(1 | Subject) + (0 + scTrial | Subject) +
(1 | Page ) + (1 | Word),
data = lexdec_corr) )
## Linear mixed model fit by REML ['lmerMod']
## Formula: scRT ~ scTrial + NativeLanguage * Class + (1 | Subject) + (0 +
## scTrial | Subject) + (1 | Page) + (1 | Word)
## Data: lexdec_corr
## REML criterion at convergence: 1332.278
## Random effects:
## Groups Name Std.Dev.
## Word (Intercept) 0.15957
## Subject scTrial 0.06154
## Subject.1 (Intercept) 0.25953
## Page (Intercept) 0.91918
## Residual 0.33317
## Number of obs: 1594, groups: Word, 79; Subject, 21; Page, 10
## Fixed Effects:
## (Intercept) scTrial NativeLanguage1
## 0.028270 -0.018845 -0.151288
## Class1 NativeLanguage1:Class1
## 0.004054 -0.020705
( model_r2 <- lmer(scRT ~ scTrial + NativeLanguage*Class +
(1 | Subject) + (1 | Page ) + (1 | Word),
data = lexdec_corr) )
## Linear mixed model fit by REML ['lmerMod']
## Formula: scRT ~ scTrial + NativeLanguage * Class + (1 | Subject) + (1 |
## Page) + (1 | Word)
## Data: lexdec_corr
## REML criterion at convergence: 1355.618
## Random effects:
## Groups Name Std.Dev.
## Word (Intercept) 0.1592
## Subject (Intercept) 0.2594
## Page (Intercept) 0.9201
## Residual 0.3386
## Number of obs: 1594, groups: Word, 79; Subject, 21; Page, 10
## Fixed Effects:
## (Intercept) scTrial NativeLanguage1
## 0.027711 -0.018250 -0.150050
## Class1 NativeLanguage1:Class1
## 0.004416 -0.022035
( model_r3 <- lmer(scRT ~ scTrial + NativeLanguage*Class +
(1 | Subject) + (1 | Page ),
data = lexdec_corr) )
## Linear mixed model fit by REML ['lmerMod']
## Formula: scRT ~ scTrial + NativeLanguage * Class + (1 | Subject) + (1 |
## Page)
## Data: lexdec_corr
## REML criterion at convergence: 1505.341
## Random effects:
## Groups Name Std.Dev.
## Subject (Intercept) 0.2578
## Page (Intercept) 0.9216
## Residual 0.3686
## Number of obs: 1594, groups: Subject, 21; Page, 10
## Fixed Effects:
## (Intercept) scTrial NativeLanguage1
## 0.021985 -0.017193 -0.147368
## Class1 NativeLanguage1:Class1
## 0.003753 -0.022888
# modellek összevetése
anova(model_r3, model_r2, model_r1, model_full, refit = FALSE)
## Data: lexdec_corr
## Models:
## model_r3: scRT ~ scTrial + NativeLanguage * Class + (1 | Subject) + (1 |
## model_r3: Page)
## model_r2: scRT ~ scTrial + NativeLanguage * Class + (1 | Subject) + (1 |
## model_r2: Page) + (1 | Word)
## model_r1: scRT ~ scTrial + NativeLanguage * Class + (1 | Subject) + (0 +
## model_r1: scTrial | Subject) + (1 | Page) + (1 | Word)
## model_full: scRT ~ scTrial + NativeLanguage * Class + (1 + scTrial | Subject) +
## model_full: (1 | Page) + (1 | Word)
## Df AIC BIC logLik deviance Chisq Chi Df Pr(>Chisq)
## model_r3 8 1521.3 1564.3 -752.67 1505.3
## model_r2 9 1373.6 1422.0 -677.81 1355.6 149.72 1 < 2.2e-16 ***
## model_r1 10 1352.3 1406.0 -666.14 1332.3 23.34 1 1.358e-06 ***
## model_full 11 1351.9 1411.0 -664.96 1329.9 2.35 1 0.1253
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
# AIC
AIC(model_r3, model_r2, model_r1, model_full)
## df AIC
## model_r3 8 1521.341
## model_r2 9 1373.618
## model_r1 10 1352.278
## model_full 11 1351.928
# BIC
BIC(model_r3, model_r2, model_r1, model_full)
## df BIC
## model_r3 8 1564.333
## model_r2 9 1421.984
## model_r1 10 1406.018
## model_full 11 1411.042
Random hatások ellenőrzése
- BLUP (best linear unbiased predictor) -> Douglas Bates inkább a "conditional mode of random effects" megfogalmazást preferálja
- a legjobb, ha a feltételes variancia-kovariancia mátrixot is kérjük, de ez többtagú random hatásoknál egyelőre nem működik
ranefs <- ranef(model_r1, condVar = TRUE)
## Warning in ranef.merMod(model_r1, condVar = TRUE): conditional variances
## not currently available via ranef when there are multiple terms per factor
library(lattice) # az ábrázoláshoz betöltjük a lattice csomagot
dotplot(ranefs)
## $Word
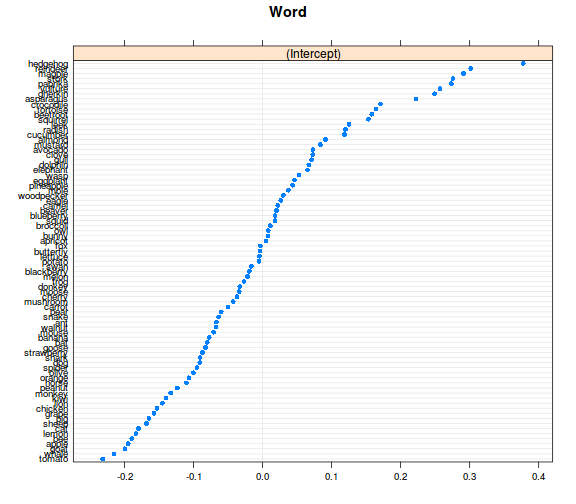
##
## $Subject
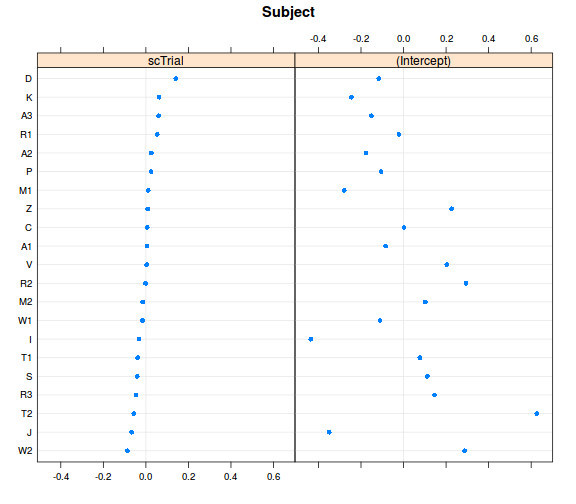
##
## $Page
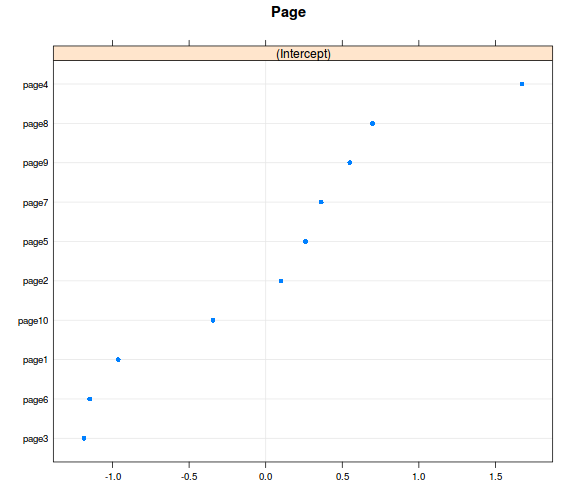
# ennél a modellnél stimmel a dolog
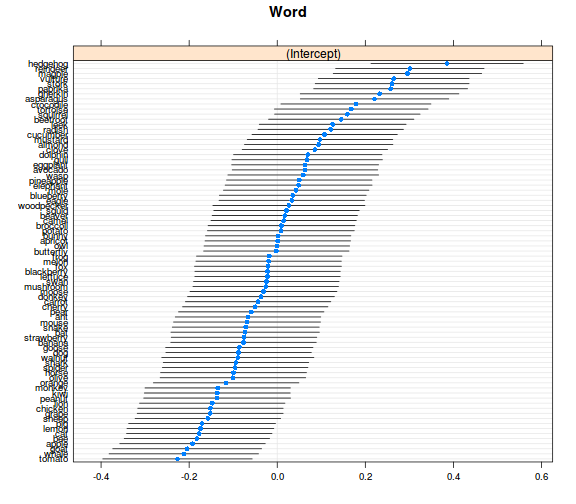
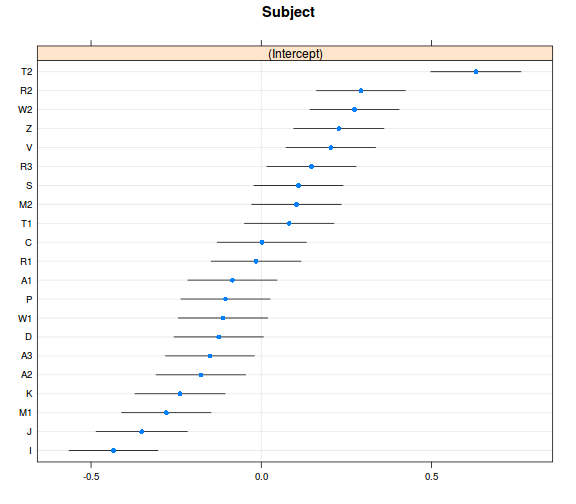
ranefs_vcov <- ranef(model_r2, condVar = TRUE)
dotplot(ranefs_vcov)
## $Word
##
## $Subject
##
## $Page
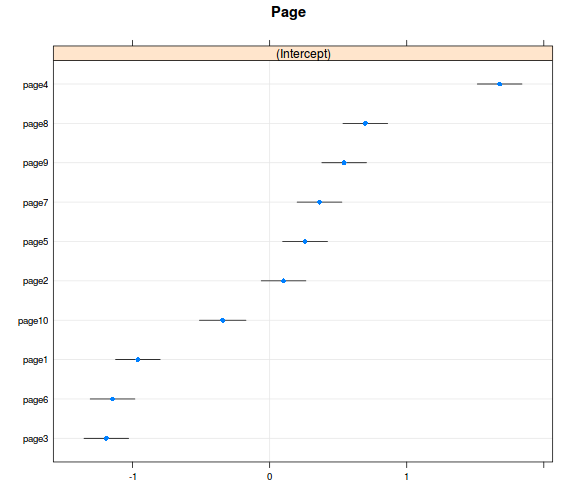
- összességében azt látjuk, hogy a random hatások valóban számottevő mértékűek
- ellenőrizzük a reziduálisokat (normál eloszlásúak-e, van-e szélsőséges érték):
resids <- scale(residuals(model_r1))
par(mfrow = c(1, 2))
hist(resids) # sima hisztogram
qqnorm(resids) # Q-Q ábra a normalitás ellenőrzésére
qqline(resids)
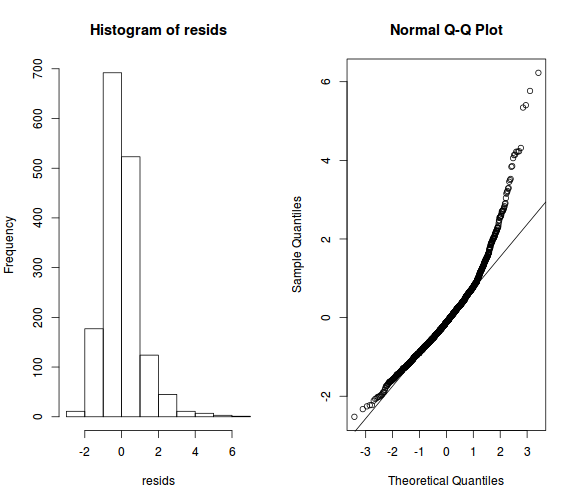
- a reziduálisok alapján megfontolandó lenne, hogy a válaszidők logaritmusa helyett azok inverz transzformáltjával számoljunk, vagy esetleg zárjuk ki azokat az eseteket, amelyeknél a standardizált reziduális túllép egy bizonyos értéket (pl. 2,5-öt)
- válasszuk ki a végső modellt
model_ranef_final <- model_r1
Fix hatások tesztelése
- a legkényelmesebb módszer: best subset; FIGYELEM, ésszel használjuk!!!
- mivel most a fix hatásokat teszteljük, sima ML becslést (nem pedig REML-t) kell alkalmazni
library(MuMIn)
options(na.action = "na.fail") # ez kell, különben a dredge fv. panaszkodik
# Alapesetben az ML megoldható az update() függvénnyel
model_ranef_final_ml <- update(model_ranef_final, REML = FALSE)
# Modellek illesztése
( fixmodels <- dredge(model_ranef_final_ml) )
## Fixed term is "(Intercept)"
## Global model call: lmer(formula = scRT ~ scTrial + NativeLanguage * Class + (1 |
## Subject) + (0 + scTrial | Subject) + (1 | Page) + (1 | Word),
## data = lexdec_corr, REML = FALSE)
## ---
## Model selection table
## (Int) Cls NtL scT Cls:NtL df logLik AICc delta weight
## 12 0.028210 + + + 9 -654.596 1327.3 0.00 0.357
## 16 0.028230 + + -0.01883 + 10 -653.884 1327.9 0.60 0.264
## 3 0.028820 + 7 -657.525 1329.1 1.81 0.144
## 7 0.028810 + -0.01874 8 -656.831 1329.8 2.45 0.105
## 4 0.028680 + + 8 -657.524 1331.1 3.83 0.052
## 8 0.028690 + + -0.01873 9 -656.830 1331.8 4.47 0.038
## 1 0.006837 6 -660.686 1333.4 6.12 0.017
## 5 0.006839 -0.01875 7 -659.990 1334.0 6.74 0.012
## 2 0.006697 + 7 -660.684 1335.4 8.13 0.006
## 6 0.006725 + -0.01874 8 -659.989 1336.1 8.76 0.004
## Models ranked by AICc(x)
## Random terms (all models):
## '1 | Subject', '0 + scTrial | Subject', '1 | Page', '1 | Word'
- az eredmények azt mutatják, hogy a Trial változónk hatása nem szignifikáns, és erősen határeset a Class főhatása és a NativaLanguage X Class interakció is
- tegyuk fel, hogy az scTrial-t kontrollváltozóként mindenképpen szerepeltetni akarjuk, és kérjük a BIC kritériumot is
( fixmodels2 <- dredge(model_ranef_final_ml,
rank = "AIC", extra = "BIC", fix = "scTrial") )
## Fixed terms are "scTrial" and "(Intercept)"
## Global model call: lmer(formula = scRT ~ scTrial + NativeLanguage * Class + (1 |
## Subject) + (0 + scTrial | Subject) + (1 | Page) + (1 | Word),
## data = lexdec_corr, REML = FALSE)
## ---
## Model selection table
## (Int) Cls NtL scT Cls:NtL BIC df logLik AIC delta weight
## 8 0.028230 + + -0.01883 + 1382 10 -653.884 1327.8 0.00 0.628
## 3 0.028810 + -0.01874 1373 8 -656.831 1329.7 1.89 0.244
## 4 0.028690 + + -0.01873 1380 9 -656.830 1331.7 3.89 0.090
## 1 0.006839 -0.01875 1372 7 -659.990 1334.0 6.21 0.028
## 2 0.006725 + -0.01874 1379 8 -659.989 1336.0 8.21 0.010
## Models ranked by AIC(x)
## Random terms (all models):
## '1 | Subject', '0 + scTrial | Subject', '1 | Page', '1 | Word'
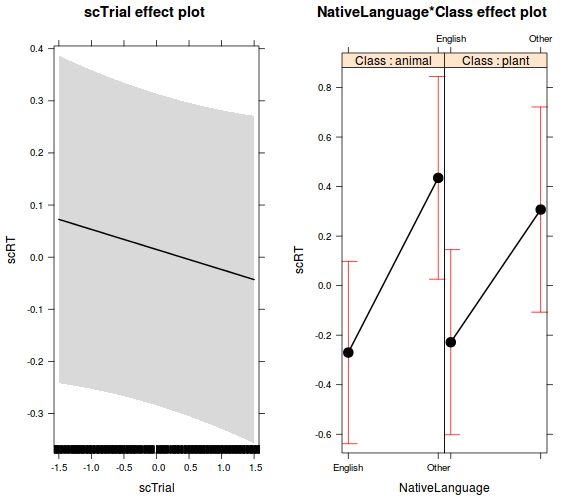
Fix hatások ábrázolása
- az effects package mindenféle modellre (köztük a merMod modellekre is) tud ábrát készíteni
library(effects)
effs <- allEffects(model_ranef_final)
plot(effs)